バラツキのロバスト統計量(1)- IQR
データの平均値、中央値ではデータ中心位置の外れ値にロバストな統計量を記載しました。バラツキに関してもロバスト(ノンパラメトリック)な統計量があります。IQRとMADと言ったものですが、今回はIQRと標準偏差推定時の補正値について書きます。
IQR(四分位範囲)
外れ値の影響を受けにくいロバストな統計量としては四分位偏差(IQR, InterQuartile Range)があります。IQRとは第三四分位数と第一四分位数の差です。言い換えるとデータをソートした25パーセンタイルと75パーセンタイルの差分になります。
[math] \displaystyle IQR = x_{75\%} - x_{25\%} [/math]
箱ひげ図(Boxplot)において箱の上端は第三四分位数、下端は第一四分位数なので、IQRとは視覚的には箱ひげ図の箱の長さです。
IQRから標準偏差の推定
IQRは標準偏差=1の正規分布において1.3489となります。このためIQRを1.3489で割った(0.7413をかけた)Normalized IQR(NIQR)が定義され、外れ値に影響を受けにくい標準偏差の推定値となります。
[math] \displaystyle NIQR = IQR \div 1.3489 [/math]
[math] \displaystyle NIQR = 0.7413 \times IQR [/math]
IQRから標準偏差の推定補正
IQRから標準偏差を推定できると前節で書きましたが、特に少数のサンプルサイズによって見積もり精度に偏りが生じます。
例えば平均=0、標準偏差=1の正規分布に従う乱数から生成したデータについて、NIQRを計算したのが下記です。横軸はサンプルサイズで1000回試行の結果です。標準偏差=1なので、縦軸は1が正解ですがサンプルサイズによってバラついているのが分かります。

対象データを正規分布と仮定すると補正値が提案されており[1]、下記形式で補正を[math] \displaystyle d_n [/math]と置いて、下記のような数値となります。
[math] \displaystyle \hat{\sigma} = \frac{\overline{IQR}}{d_n} [/math]

補正結果は下記のようになり、元々の標準偏差=1に綺麗に近づいています。ズレ分を補正しただけなので当然なのですが、ノンパラメトリックな要約量の場合、少数サンプルの偏りが大きめ出たり小さめに出たりとと注意が必要です。実務上で、本事例で困ったことはないですが。。。

まとめ
四分位偏差(IQR)から標準偏差を推定する場合の補正値について述べました。今回も、こちらのツールに実装しています、Menu > Open File (Normality Test)などで読み込むと他の統計値と一緒に計算します。
[1] Transformation and normalization of oligonucleotide microarray data, Sue C. Geller, Jeff P. Gregg, Paul Hagerman, David M. Rocke Bioinformatics, Volume 19, Issue 14, 22 September 2003, Pages 1817–1823,
箱ひげ図 ー ボックス間の接続
箱ひげ図では条件間を平均値などで接続する場合があります。
箱ひげ図とボックス間の接続
箱ひげ図(Boxplot)とは、バラツキを含むデータを上手く要約して可視化したものです。

箱ひげ図の派生型の中で、平均値などで条件間を接続する場合があります。例えば箱ひげ図の箱の中央を形成する中央値を接続してみます。

箱ひげ図の定義から離れて平均値で条件間を接続するケースもあります。

他に平均値、中央値の代替となるものとして、トリム(刈り込み)平均もあります。トリム平均はデータをソートした後、両端A/2 %削除した後に平均を計算するもので、これをA%トリム平均などと呼びます。トリム平均は、外れ値がなければ最尤推定の平均値と、外れ値に頑健な中央値の、中庸な性質となります。下記に50%トリム平均で接続した結果を示します。

平均値、中央値、トリム平均全て表示すると下記、見慣れると生データの雰囲気も良そう出来るようになります。

箱ひげ図に本来表示されない平均値とその信頼区間を黒枠ひし形で表す場合があるので、箱ひげ図での条件間接続と一緒に表示すると下記です。少しわかりやすくなったと思いますが、如何でしょうか?

まとめ
箱ひげ図のヴァリエーションについて紹介しました。今回は条件ごとボックス間の中心地接続表示でした。今回のツールは、こちらのツールに置いています。
箱ひげ図 ー ドットプロット
箱ひげ図のオプションについて、取得データをドットプロットで表示する場合があります。
箱ひげ図
箱ひげ図(Boxplot)とは、バラツキを含むデータを上手く要約して可視化したものです。統計的に信頼できるデータのバラツキを箱、判断に迷うものをヒゲとして表します。

取得データをドットプロット
箱ひげ図は必要最低限の情報を要約して可視化したものです。追加のオプションとして元のデータをなるべく表示するアプローチがあります。例えば、個別データを中心位置は箱ひげ図と同一としてある規則で散らばらせて表示する手法です。

上記のように箱ひげ図と重ねると折角表した全てのデータ点が不明瞭になります。このため、表示位置をズラした可視化方法が考えられます。箱ひげ図のボックスとずらすとこのような感じです。

まとめ
箱ひげ図のヴァリエーションについて紹介しました。今回のツールは、こちらのツールに置いています。個人的には表示位置をずらした方が分かりやすいと思います。
正規確率プロット縦軸表示方法
箱ひげ図と並んで、バラツキを含んだデータの代表的な可視化手法である正規確率プロットについて、縦軸表示の派生型を説明します。
正規確率プロット
正規確率プロットとはQ-Qプロット(quantile-quantile plot)の一種です。Q-Qプロットとは期待している確率分布と実データの対応を可視化したものです。大抵の場合我々は正規分布を期待するので、正規分布ベースの正規Q-Qプロット(正規確率プロット)を使うことが多いです。プロット結果が直線なら「期待した確率分布に従う」ということが言えます。
※故障確率で使うWeibull分布を使ったWeibull potや、半導体分野では電圧-電流特性が所望の特性か確認する***plot(fowler-nordheim plot, poole-frenkel plot)、Tr.特性バラツキに関するperglom plotなど「何とかプロット」というのは沢山あります。共通して言えるのはプロットが「考えているモデルが正しければ直線になるプロット」です。直線かどうかで視覚的にとらえやすくしています。
正規確率プロットの可視化方法
正規確率プロットでは横軸に計測値などの数値データをソートしたもの、縦軸に各点のパーセント或いは確率を表示します。ただし縦軸の表示は確率に対して線形ではなく、正規分布の累積密度関数の逆関数により変換したスケールを用います。正規分布の幅を決めるパラメータが標準偏差でこれをシグマという記号を使って表しますが、各確率が1シグマの何倍に相当するか計算します。
[math] \displaystyle Sigma = Normsinv(probability) [/math]
シグマ値は0シグマが確率0.5で、1シグマが確率0.68、2シグマが確率0.95、3シグマが確率0.997に相当します。こちら68–95–99.7則の記事に少し記載しています。
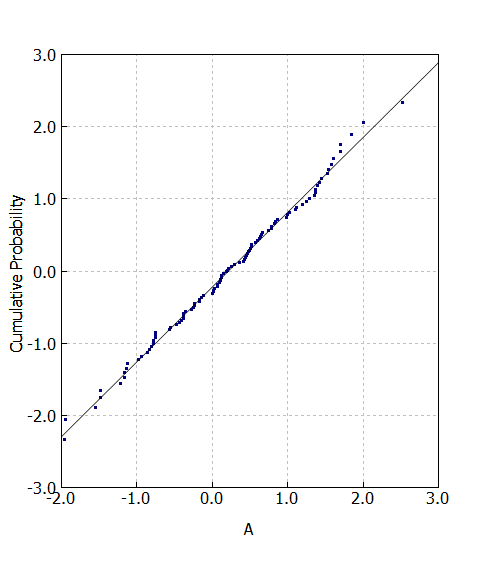
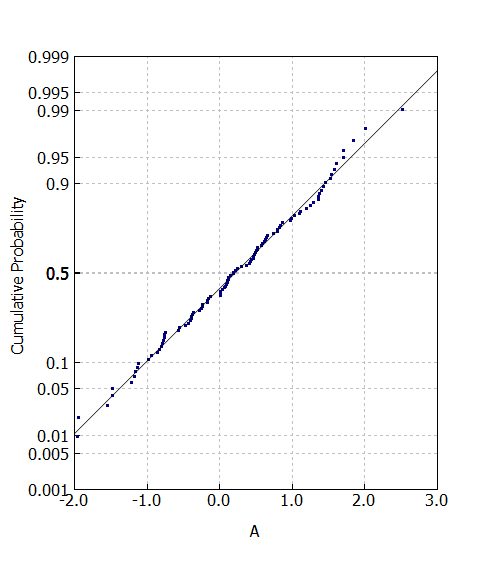
まとめ
今回の可視化方法は、こちらのツールに実装しています。論文ベースでは縦軸確率も多いですが、確率だと小数点の桁数表示が細かくなるので非効率的に思います。ただし、シグマと確率の相対関係を頭に入れておくのが前提なのでTPOを選んで使い分けるべきなのでしょうね。
いかにして問題をとくか(2)
G.ポリアの「いかにして問題をとくか」から問題解決のアプローチ方法を図示します。
G.ポリアの2.「計画を立てること」
未解決課題があるとして、G.ポリアの「計画を立てること」が大変参考になります。要約してみると下記のようになります。本書は問題解決の技法を言い換えながら何度も別の表現方法で書き表しています。数学者がこのように書いているので、おそらく意図的なのでしょう。
類似/類推/関連/簡略化/一般化/特殊/部分 問題はないか
制約条件の変更(影響範囲)
未使用データ/不足データ/全て考慮したか?
課題自体の分解、一般化、特殊化、そして制約条件も分解してみる。手持ちのデータを使いつくしたか、反証/検証しつくしたか。
これを図示してみると、こんな感じなのではないかと思います。

原著には部分問題にしてみたり一般化してみたり、そういう事が書かれていますがそれは分かります。そして「条件の一部を捨てよ」とか「易しくして」のような表現があり、自分はこれがとても胸に響きました。実験系で考察を進めると実験誤差、測定器誤差、未成熟な評価手法にも出くわします。与えられた事実を全て満たさないケーススタディは実はとても重要です。
まとめ
G.ポリアの名著「いかにして問題をとくか」の「計画を立てること」に基づいて、思考方法を可視化してみました。やっぱり図にしてみたらとても良いと思うので改良、批判お願いします。
いかにして問題をとくか(1)
言わずと知れたG.ポリアの名著「いかにして問題をとくか」です。柿内賢信訳の書籍表紙見返りには要約がついています。まずはそこから
「いかにして問題をとくか」の要約
有名な訳は以下です、ちょっと多いのであとで圧縮してみます。
1.問題を理解すること
未知のものは何か、与えられているデータは何か、条件の各部を分離し書きあらわせ。
○未知のものは何か。与えられているもの(データ)は何か。条件は何か。
○条件を満足させうるか。 条件は未知のものを定めるのに十分であるか。または、不十分であるか。または、余剰であるか。矛盾しているか。
○図をかけ。適当な記号を導入せよ。
○条件の各部を分離せよ。それを書き表すことができるか。
2.計画を立てること
与えられた問題が解けなかったら、既に解いたことのある易しくて似た問題を思い出せ。条件の一部を残し他を捨てれば未知のものが見えてくる。
○前にそれをみたことがないか。同じ問題を少しちがった形で見たことがないか。
○似た問題を知っているか。
○役に立つ定理を知っているか。
○未知のものをよく見よ。そして、未知のものが同じかまたは、よく似ている見慣れた問題を思い起こせ。
○似た問題ですでに解いた事のある問題がここにある。それを使うことができないか。その結果を使うことができないか。その方法を使うことができないか。それを利用するためには、何か補助要素を導入すべきではないか。
○問題を言い換えることができるか。それをちがったいい方をすることができないか。
○定義にかえれ。
○もし与えられた問題が解けなかったならば、何かこれと関連した問題を解こうとせよ。
○もっと易しくてこれに似た問題は、考えられないか。
○もっと一般的な問題は?もっと特殊な問題は?類推的な問題は?
○問題の一部分を解くことができるか。
○条件の一部を残し、他をすてよ。そうすればどの程度まで未知のものが定まり、どの範囲で変わりうるか。
○データを役立させうるか。
○未知のものを定めるのに適当な他のデータを考えることができるか。
○未知のものもしくはデータ、あるいは必要ならば、その両方を変えることができるか。そして、新しい未知のものと、新しいデータとが、もっと互いに近くなるようにできないか。
○データをすべてつかったか。
○条件のすべてをつかったか。
○問題に含まれる本質的な概念は、すべて考慮したか。
3.計画を実行すること
計画を実行せよ。
○解答の計画を実行するときに、各段階を検討せよ。その段階が正しいことをはっきりと認められるか。
4.振り返ってみること
得られた答えを検討せよ。
○結果を試すことができるか。
○議論を試すことができるか。
○結果をちがった仕方で導くことができるか。それを一目で捉えることができるか。
○ほかの問題にその結果や方法を応用することができるか。
理系エンジニア向けへの翻案
有名なフレームワークP(plan)D(do)C(check)A(act)に対しG.ポリアの2.は(plan)、3.は(do)、4.は(check)に相当するのが現代にも通用する方法論であることの証左です。そして理系の技術者として大変参考になるのは1.と2.と思います。3.と4.は実験と考察、あるいは追加の検証になるので、ここまで到達すればある程度規定路線です。
まずはG.ポリアの1.「問題を理解すること」。これは取り掛かる未解明案件への最初のアプローチ。問題を理解出来ていなければ解明のしようがないです。また、考察を進める上での前提条件の整理でもあります。
実験結果の整理(未知のものは何か、与えられているデータは何か)
実験事実を分離する(条件の各部を分離し書きあらわせ)
そしてG.ポリアの2.「計画を立てること」は、元々の著作でも本項目だけ分量が多いです。本書の肝であるが故、比重が多く割かれているのだと思います。また、元々は数学問題へのアプローチのため数学証明のための記述があるので、技術者向けに選択・抜粋してみます。
類似/類推/関連/簡略化/一般化/特殊/部分 問題はないか
制約条件の変更(影響範囲)
未使用データ/不足データ/全て考慮したか?
課題自体の分解、一般化、特殊化、そして制約条件も分解してみる。手持ちのデータを使いつくしたか、反証/検証しつくしたか。
最終的にはストイックなフレームワークだけど、課題を理解しやすい形に変更することから始めています。実はとてもやさしい論証のフレームワークですね。
まとめ
G.ポリアの名著「いかにして問題をとくか」について、徒然に書きました。次回は図にしてみます。
2標本におけるバラツキの差の検定(3)
2標本におけるバラツキの差の検定(1)で紹介した手法を乱数でテストしてみます。正規分布に従う乱数で、外れ値を含めてみます。正規確率プロットで比較してみます。
手法と配色は下記の通りです。

正規分布で外れ値混入率を変化させて比較
サンプル数10の2群データについて、標準偏差1.0と2.0正規乱数に従う1000回試行での結果が下記です。固定値100の外れ値混入率を変化させています。





こうしてみるとF検定などは正規確率プロット上は不連続になっていて、外れ値が入った瞬間にP値が大きくなっていそうです。F検定やSukhatme検定は不自然にP値が小さく、外れ値に騙されて有意になっていそうですね。でも、この比較はちょっとよくわからないかも。。。
正規分布で外れ値の大きさを変化させて比較
今度はサンプル数10の2群データについて、標準偏差1.0と2.0正規乱数に従う1000回試行までは前節と同様で、標準偏差1.0の方のデータに一点だけ外れ値を混入、外れ値の大きさを変化させてみます。


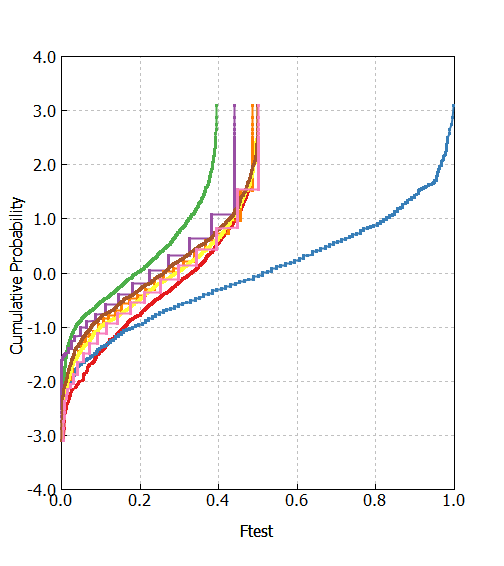
今回もF検定やSukhatme検定は不自然にP値が小さく、外れ値に騙されて有意になっていそうです。しかも標準偏差が小さい群に外れ値を混入したのですが、標準偏差が小さい群がバラツキが大きいと受け取る人もいるかもしれません。
まとめ
F検定、Mood検定、Klots検定、Savege検定、Siegel-Tukey検定、Ansari-Bradley検定、Sukhatme検定については、こちらのツールに実装しています。今回の比較では、F検定、Sukhatme検定あたりに差が出ました。F検定はともかく、Sukhatme検定も意外と外れ値に敏感なんですね。。。