ミッドレンジについて特性を確かめてみます。
ミッドレンジ
統計学においてミッドレンジ(mid-range)は分布中心を推定する指標の一つにです。具体的には最大値と最小値の中心値(平均値)です。
この定義を聞いて想像される通り、ミッドレンジは外れ値に弱いです。ロバストではありません。本来の母集団とは大きく異なる外れ値は最大値/最小値を大きく変化させるため、ミッドレンジも影響を大きく受けます。このため実用上でミッドレンジを扱うことはほとんどありません。
ただし特殊なケースではミッドレンジは有用となりえます。解析対象が正規分布ではなく一様分布の場合、ミッドレンジは効率的な中心値の推定値となるようです[1]。
またトリムミッドレンジもあります。トリム平均(刈り込み平均)と同様に解析データをソートを両端をある割合で削除しミッドレンジを計算します。20%ミッドレンジならデータソート後に両端10%ずつ削除後ミッドレンジを計算します。ちなみに中央値は50%ミッドレンジと捉えることも出来ます。
計算例
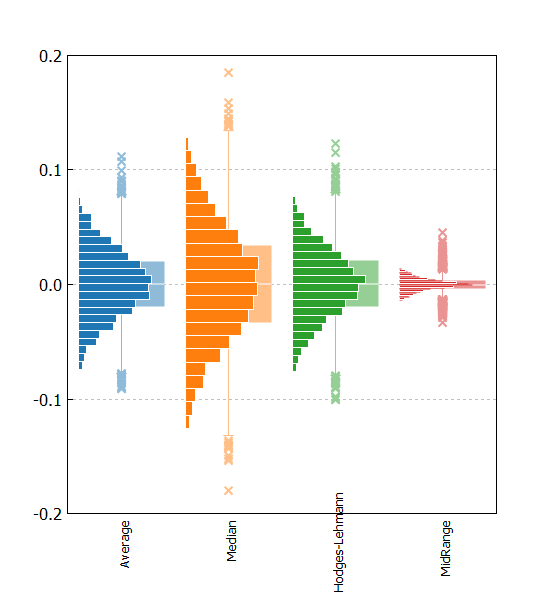
平均=0、標準偏差=1の正規乱数データ100点について、(1)Average、(2)median、(3)Hodges-Lehmann、(4)Mid-Rangeを計算します。5000回試行した計算結果の箱ひげ図を下記に示します。
やはりミッドレンジのバラツキが大きいです。

続いて(-0.5,0.5)の一様乱数データ100点について、(1)Average、(2)median、(3)Hodges-Lehmann、(4)Mid-Rangeを計算してみます。5000回試行した計算結果の箱ひげ図を下記に示します。
確かに一様分布に限定するとミッドレンジは精度の高い中心位置推定が行えるようです。
まとめ
バラツキの大きそうなミッドレンジですが、確かに一様分布の場合は強力ですね。機械学習などもありますが、翻って見ると解析対象に適した手法を用いるのが一番効率的なんだろうと思います。ノーフリーランチ定理[2]的な感じです。
[1]https://en.wikipedia.org/wiki/Mid-range
[2]https://ja.wikipedia.org/wiki/%E3%83%8E%E3%83%BC%E3%83%95%E3%83%AA%E3%83%BC%E3%83%A9%E3%83%B3%E3%83%81%E5%AE%9A%E7%90%86