ロバスト(M推定量)な回帰
平均値に対する中央値のように、統計解析手法の中には外れ値に影響を受けにくいロバストな手法があります。回帰分析においてはPassing and Bablokの方法と、Theil-Sen's imcomplete methodをこちらで紹介しました。これらの手法は正規分布なども仮定しない完全にノンパラメトリックな手法ですが、最小二乗法に対し上手く重みづけを行い、外れ値にロバストなM推定量に基づく回帰を紹介します。
繰り返し最小二乗法とM推定
単回帰分析ではYの誤差を最小化します。最小二乗法による係数の求め方は下記でした。
[math] \displaystyle \min f=\sum_{i=1}^{n} \{ y_i - (ax_i+b) \}^2 [/math]
上式のa,bについて偏微分=0から
[math] \displaystyle \sum_{i=1}^{n} {x_i}^2 \cdot {a} + \sum_{i=1}^{n} {x_i} \cdot {b} = \sum_{i=1}^{n} {x_i y_i} [/math]
[math] \displaystyle \sum_{i=1}^{n} {x_i} \cdot {a} + n \cdot {b} = \sum_{i=1}^{n} {y_i} [/math]
この連立方程式を行列表示すると
[math]\displaystyle \left( \begin{matrix} {\sum_{i=1}^{n} {x_i}^2} & {\sum_{i=1}^{n} {x_i}} \\ {\sum_{i=1}^{n} {x_i}} & n \end{matrix} \right) \left( \begin{matrix} a \\ b \end{matrix} \right) \left( \begin{matrix} \sum_{i=1}^{n} {x_i y_i} \\ \sum_{i=1}^{n} {y_i} \end{matrix} \right)[/math]
・・・添え字は省略
[math]\displaystyle \left( \begin{matrix} {\sum {x_i}^2} & {\sum {x_i}} \\ {\sum {x_i}} & n \end{matrix} \right) \left( \begin{matrix} a \\ b \end{matrix} \right) \left( \begin{matrix} \sum {x_i y_i} \\ \sum {y_i} \end{matrix} \right)[/math]
上式はもちろん解析に解けます。これに対し外れ値データの重みを小さく(あるいは0に)する[math] w_i [/math]を付加します。
[math]\displaystyle \left( \begin{matrix} {\sum {w_i x_i}^2} & {\sum {w_i x_i}} \\ {\sum {w_i x_i}} & {\sum {w_i}} \end{matrix} \right) \left( \begin{matrix} a \\ b \end{matrix} \right) \left( \begin{matrix} \sum {w_i x_i y_i} \\ \sum {w_i y_i} \end{matrix} \right)[/math]
ここでモデル式による予測値と観測値の誤差大きい場合、重みを小さくすることを考えます。この場合、[math] w_i [/math]はモデル式が分からないと計算できません。そこで仮決めのモデル式から誤差を計算し反復計算で収束させます。このアプローチは最小二乗法を繰り返すことになるので、繰返し(加重)最小二乗法(IRLS: Iteratively Reweighted Least Squares)と呼ばれます。
M推定と呼ばれる手法は上記のように推定を行い、重み付け関数に誤差項を乗じたものを核関数と呼びます。
Tukey型(Biweight)の重み付け関数
Tukey型の重み付け関数は下記の通り、尺度パラメータより誤差が大きい場合重み=0で完全に無視する取り扱いです。尺度パラメータを[math]c[/math]と置きます。
[math] \displaystyle
{w_i} =
\begin{cases}
\displaystyle (1-\frac{{e_i}^2}{c^2})^2 & (|e_i| \le c) \\
\displaystyle 0 & (|e_i| \gt c)
\end{cases}
[/math]
bisquare型あるいはbiweight型とも呼ばれるようです。
刈り込み型の重み付け関数
重み=1 or 0の刈り込み平均に相当する重み付け関数もあります。
[math] \displaystyle
{w_i} =
\begin{cases}
\displaystyle 1 & (|e_i| \le c) \\
\displaystyle 0 & (|e_i| \gt c)
\end{cases}
[/math]
Huber型の重み付け関数
Huber型の重み付け関数は尺度パラメータを[math]c[/math]としたとき下記です。
[math] \displaystyle {w_i} = \begin{cases} 1 & (|e_i| \le c) \\ \displaystyle \frac {c} {|e_i|} & (|e_i| \gt c) \end{cases} [/math]
繰り返し最小二乗法において誤差が尺度パラメータ以下の場合は重み=1なので通常の二乗誤差と同等になります。誤差が大きい場合は二乗項に誤差の逆数の重みがかかるので絶対誤差を最小化していることになります。
回帰分析例
定義域[0.2,1.2]のY=Xにおいて、Y方向のみに標準偏差0.1の正規分布乱数を与えた300点のデータを用意し、XとYについて区間[0,1.4]の無相関な一様乱数ノイズデータを30点加えたまし。本データに対し、Passing-Bablock、Theil-Sen's imcomplete method、RANSAC、M推定量に基づく回帰(TukeyのBiweight型)を適用した結果を示します。それぞれ黒線は通常の最小二乗法(OLS)です。OLSの場合、無相関なノイズデータに引っ張られて傾きが寝ています。ロバスト回帰手法に関しては10%程度のノイズ成分では、どの手法も影響を受けずにY=Xを推定出来ています。

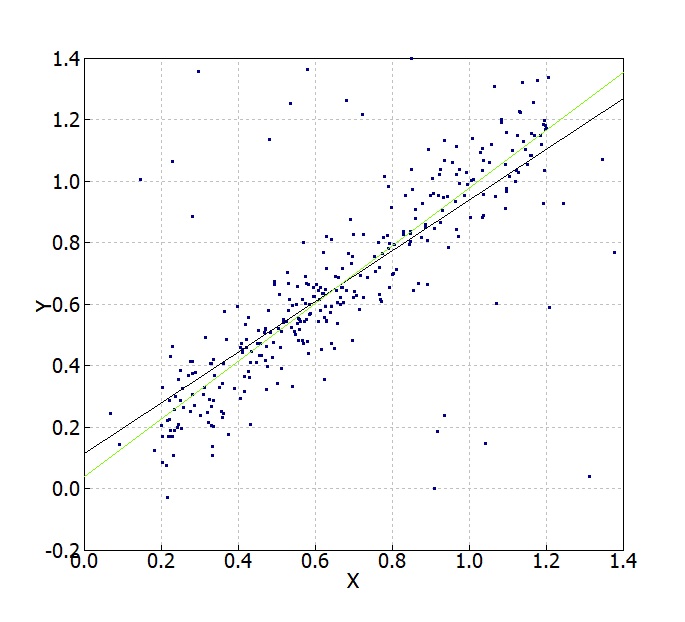
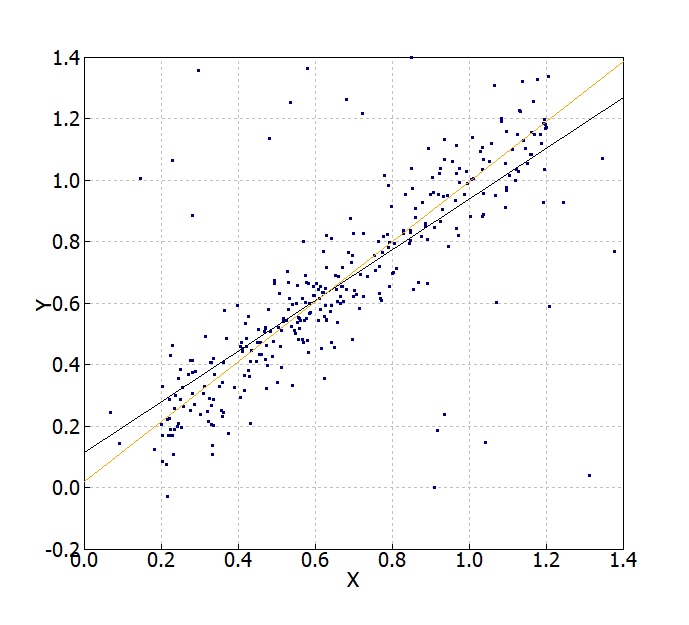

今度は一様乱数ノイズデータを150点加えたデータ例を示します。25%ぐらいノイズが混じるとTail-Senの方法などY=Xからの乖離が大きめに見えます。(もちろんたったの一例なので、常にこうなるわけではありません。)




次は一様乱数ノイズデータを300点加えたデータ例です。50%ぐらいノイズが混じるとM推定も乖離が目立ち、Y=Xに対して対照なノイズを加えているせいかPassing-Bablockが健闘しています。




先ほどはY=Xに対して対照なノイズだったので、今度は一様乱数をY>Xに限定してノイズを150点加えてみます。本データではRANSACとM推定の推定精度が高いようです。Passing-BablockもTheil-Senもノンパラメトリックとはいえデータの取捨選択は行わないので、ノイズデータに引っ張られています。
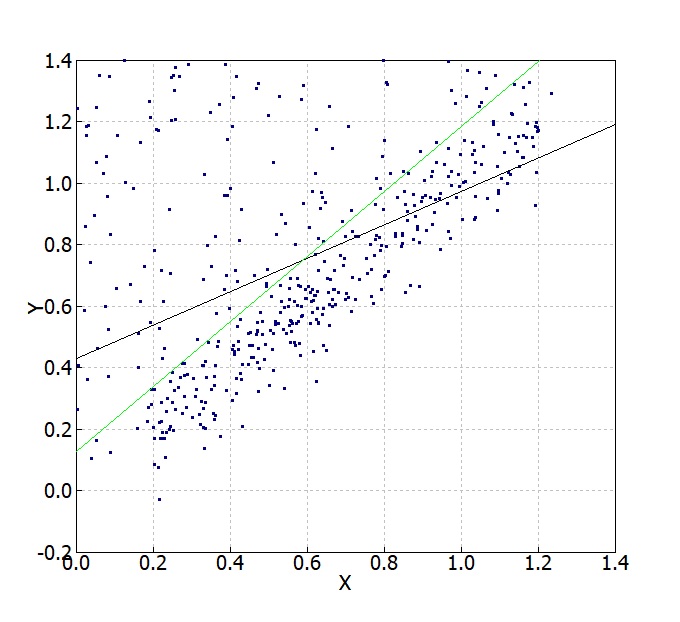



最後に無相関なノイズではなく、300点のY=Xデータに対して、Y=2X+1のデータを150点加えてみます。全てYに標準偏差0.1の正規分布乱数をノイズとして加えています。本データでもRANSACとM推定の推定精度が高いようです。先ほどと同様にPassing-BablockもTail-Senもノイズデータに引っ張られ気味で、全データの中心付近を通る直線を描く傾向がよくわかります。Theil-Senの方法は傾きだけはY=Xを抽出出来ているように見えます。RANSACとM推定では、RANSACの方がY=Xを捉えらているように見えますが、この辺りは尺度パラメータの取り方での変動範囲内と思います。




まとめ
M推定量に基づく回帰分析を紹介しました。回帰分析といっても色々な手法があり一長一短です。まずは様々な手法が存在することを認識して、分析に困ったときに思い出せると良いのではないかと思います。こちらでは様々な回帰を実装しています。他手法との比較も出来るようにしています。遊んでみてください。