多群の等分散性検定(1)ー Bartlett/Levene/Brown-Forsythe/O'Brien/Hartley
実験結果について比較を行う場合、平均値(中央値)の比較を行うことが多いですが、バラツキ(分散)の比較を行うこともあります。特に製造分野に関わっていると、バラツキ含めたワースト状況でどちらの特性が良いかは非常に重要です。一定以上の特性を持つ製品の収率を考えることはコストに直結し、コストは企業活動に直結するからです(この辺の考え方は半導体っぽいですね)。他には、例えば分散分析など、分析対象の等分散性を仮定しているものもあり、等分散性を検証する必要がある場面も少なくないです。
Bartlett(バートレット)検定
Bartlett検定[1]の帰無仮説は"全ての群の分散が等しい"です。P値が有意水準より小さい場合(例えば<0.05)、多群のデータについて何れかの分散は等しくないです。Bartlett検定は正規分布からの逸脱に対して敏感で、正規分布に従わない標本では分散が均一かどうかよりもその非正規性を検出する傾向があるそうです。正規分布かどうかにそれほど敏感でないルビーン検定 (Levene test)などもあります。
Bartlett検定の検定統計量は[math] k [/math]を群の数、[math] n_j [/math]を各群のデータ数、[math] N [/math]を全データ数、[math] \displaystyle {\sigma_i}^2 [/math]を各郡の標本分散とした時、
[math] \displaystyle {\chi}^2 = (N-k)ln( \frac{1}{N-k} \sum_{j=1}^{k}{(n_j-1){{\sigma_i}^2}}) - \sum_{j=1}^{k} {(n_j-1){ln({\sigma_i}^2)}} [/math]
[math] \displaystyle C = 1 + \frac{1}{ 3(k-1) } ( \sum_{j=1}^{k} \frac{1}{n_j-1} - \frac{1}{N-k}) [/math]
[math] \displaystyle {\chi_0}^2 = \frac {{\chi}^2}{C} [/math]
このとき、自由度[math] \displaystyle k-1 [/math]の[math] \displaystyle {\chi}^2 [/math]分布に従うことからP値を求める。
Levene(ルビーン)検定
Levene検定[2]は各グループにおける平均[math] \bar{x}_{i} [/math]とデータとの差の絶対値を応答として分散分析を実行します。
[math] \displaystyle {y_{ij}} = |x_{ij} - \bar{x}_i| [/math]
この新たな変数[math] {y}_{ij} [/math]に対して分散分析を行いますが、書き下すと下記のようになります。
[math] \displaystyle W = \frac{(N-k)}{(k-1)}
\frac { \sum_{i=1}^{k}{n_{i} (y_{ij}-\bar{y})^2}}
{ \sum_{i=1}^{k} \sum_{j=1}^{n_{i}} {(y_{ij}-\bar{y}_i)^2}} [/math]
ここで、
[math] \displaystyle \bar {y} = \frac{1}{N} \sum_{i=1}^{k} \sum_{j=1}^{n_{i}} {x_{ij}} [/math]は全ての[math] x [/math]の平均、
[math] \displaystyle \bar{y}_i = \frac{1}{n_{i}} \sum_{j=1}^{n_{i}} {x_{ij}} [/math]は第[math] i [/math]群のの平均
です。
P値は、統計量[math] W [/math]に対して自由度[math] k-1 [/math]と[math] N-k [/math]の[math] F [/math]分布から計算します。
次の下記のデータを使って、Levene検定の変数変換の様子を見てみます。元データはアヤメ(Iris)データのがく片の長さです。まずはアヤメの種類ごとに正規確率プロットします。
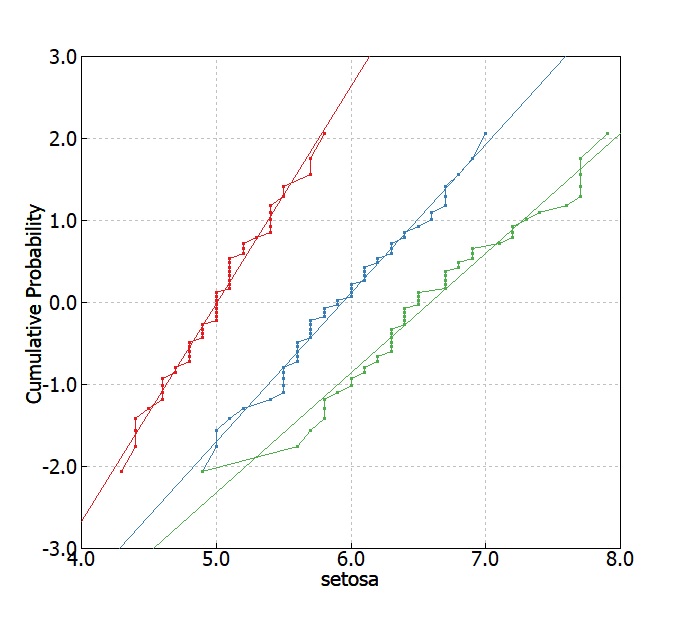
Levene検定の手続きのように平均値との差をとった変数を作成し、同様に正規確率プロットしてみます。
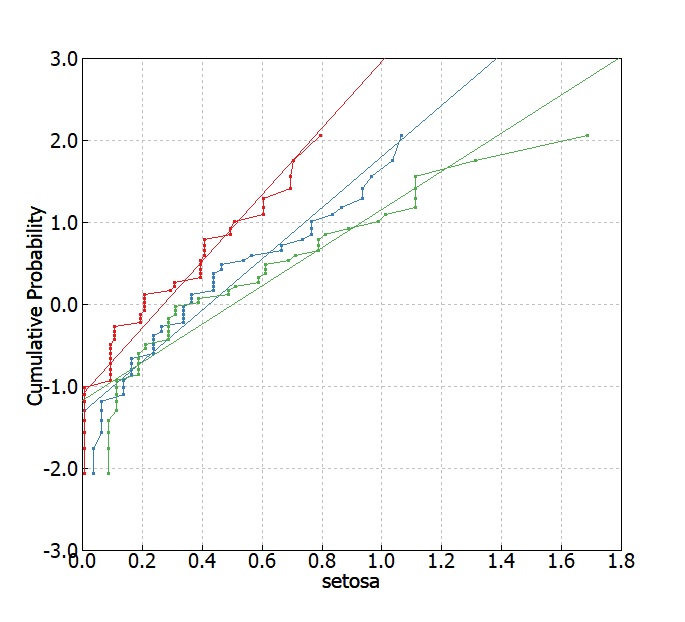
可視化結果からも緑色(viginica)がバラツキが大きそうな事がわかります。
Brown–Forsythe(ブラウン・フォーサイス)検定
Brown–Forsythe検定[3]ではLevene検定での変数変換における平均値の代わりに中央値[math] \tilde{x}_{i} [/math]を用います。後の手続きはLevene検定と全く同じように分散分析を実行します。
[math] \displaystyle {y_{ij}} = |x_{ij} - \tilde{x}_i| [/math]
容易に想像がつくように様々な分布の母集団に対してはBrown-Forsythe検定の方がLevene検定よりロバストなようです。対称で裾が重くない分布に対してはLevene検定が検出力最大になるとありますが、いつか検証してみたいと思います。
Brown-Forsythe検定とLevene検定の話を聞いていると、各種正規性検定と平均値の代わりに様々な中心代表値を代用したLevene型の検定結果をランダムフォレストなどすれば最強検定が出来そうな気がしますが、結局はノーフリーランチ定理的な事象の解像度を上げているだけのような気もします。実用上はそれだけでも十分ありがたいとは思いますが。。。
O'Brien(オブライエン)検定
O'Brien[4]での変数変換では各群の平均が各群の不偏分散と等しい従属変数が生成されます。
[math] \displaystyle {y_{ij}} =\frac
{ { (C-n_{i}-2) n_{i} (x_{ij} - \bar{x}_i)^2 - C (n_{i}-1) {\sigma_{i}}^2 } }
{ (n_{i} - 1)(n_{i} - 2) } [/math]
パラメータ[math] C [/math]は原文では0.5が提案されています。
Hartley(ハートレイ)検定
Hartley[5]検定では各郡の分散について、最大分散と最小分散の比を検定統計量とします。
[math] \displaystyle {F_{max}} =\frac { \sigma^2_{max} } { \sigma^2_{min} } [/math]
P値は最大分散比の数表より判定します。
まとめ
たまに使う代表的な等分散性検定を紹介しました。検定の前提条件だったり、あるいはワースト条件を見積もるための必要条件だったり、地味ですが重要なバラツキに関する検定でした。こちらでは今回紹介した手法の検定結果を簡便に出力するプログラムを組んでいます。遊んでみてください。
[1] Bartlett, M. S., and Kendall, D. G. (1946). “The Statistical Analysis of Variance-Heterogeneity and the Logarithmic Transformation.” Supplement to the Journal of the Royal Statistical Society 8:128–138.
[2] Levene, Howard (1960). “Robust tests for equality of variances”. In Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling, edited by I. Olkin, S. G. Ghurye, W. Hoeffding, W. G. Madow, and H. B. Mann. Palo Alto, CA: Stanford University Press. pp. 278–292.
[3] Brown, Morton B.; Forsythe, Alan B. (1974). "Robust tests for the equality of variances". Journal of the American Statistical Association. 69: 364–367.
[4] O’Brien, R. G. (1979). “A General ANOVA Method for Robust Tests of Additive Models for Variances.” Journal of the American Statistical Association 74:877–880.
[5] Hartley, H.O. (1950). The maximum F-ratio as a short cut test for homogeneity of variance, Biometrika, 37, 308-312.